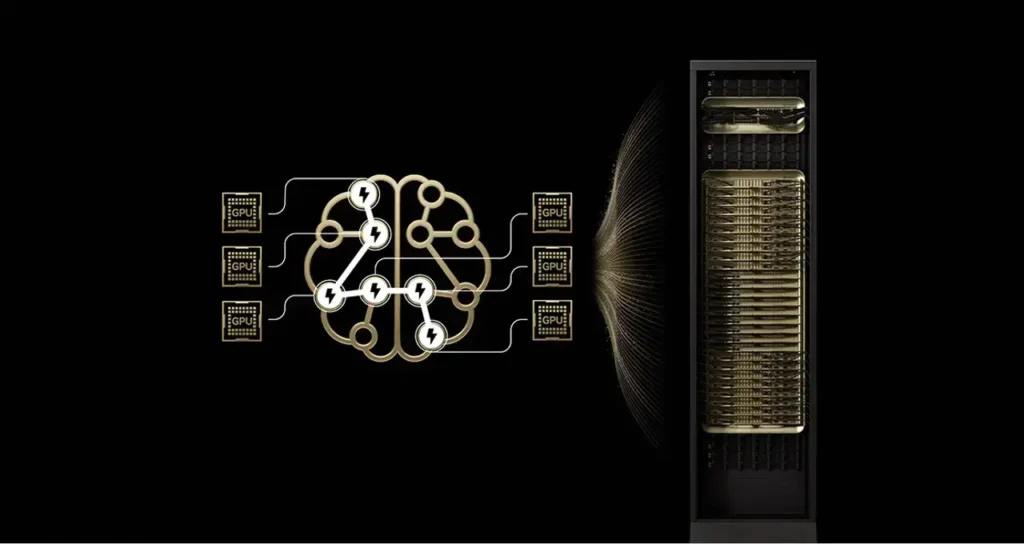
Los modelos de inteligencia artificial más avanzados usan arquitectura Mixture of Experts
Los 10 modelos de código abierto más inteligentes utilizan Mixture of Experts (MoE). Esta arquitectura, que imita la eficiencia del cerebro humano, permite generar respuestas más rápidas y eficientes. Los sistemas NVIDIA GB200 NVL72 ejecutan estos modelos, como Kimi K2 Thinking, 10 veces más rápido que la generación anterior.
La arquitectura que domina la inteligencia artificial frontera
La arquitectura Mixture of Experts (MoE) se ha convertido en el estándar para los modelos frontera. En lugar de activar todos los parámetros del modelo para cada tarea, un enrutador selecciona y activa solo a los «expertos» especializados más relevantes. Esto permite mayor inteligencia y adaptabilidad sin un aumento proporcional del coste computacional y energético. Más del 60% de los lanzamientos de modelos de IA de código abierto este año usan MoE.
Superando los cuellos de botella con diseño integral
Ejecutar grandes modelos MoE en producción presenta dificultades, como limitaciones de memoria y latencia en la comunicación entre expertos distribuidos en múltiples GPUs. La solución de NVIDIA es el diseño integral extremo del sistema GB200 NVL72. Sus 72 GPUs Blackwell conectadas con NVLink funcionan como una sola, con 30TB de memoria compartida rápida. Esto permite distribuir expertos entre hasta 72 GPUs, aliviando la presión en la memoria y acelerando la comunicación.
Un salto de rendimiento que transforma la economía de la IA
El sistema GB200 NVL72 ofrece un rendimiento 10 veces mayor por vatio para modelos MoE complejos en comparación con la plataforma Hopper anterior. Este avance no es solo técnico; posibilita multiplicar por 10 los ingresos por token, transformando la economía de la IA a gran escala. Proveedores de nube como AWS, Google Cloud y Microsoft Azure, junto con partners como CoreWeave, ya despliegan este sistema.
Casos de éxito en modelos líderes
El modelo Kimi K2 Thinking, clasificado como el más inteligente en el ranking de Artificial Analysis, experimenta un salto de rendimiento 10 veces mayor en GB200 NVL72. DeepSeek-R1 y Mistral Large 3 también logran una ganancia de rendimiento 10 veces superior respecto a la generación H200. Empresas como DeepL utilizan el hardware GB200 para entrenar sus próximos modelos MoE.
El patrón MoE define el futuro de la IA eficiente
El principio de enrutar tareas a expertos especializados se extiende más allá de los modelos de lenguaje. Los nuevos modelos multimodales y los sistemas agentivos siguen este mismo patrón. Esto apunta a un futuro con grupos compartidos de expertos accesibles para múltiples aplicaciones, maximizando la eficiencia. La hoja de ruta de NVIDIA, incluida la arquitectura Vera Rubin, continuará expandiendo los horizontes de los modelos frontera.











